比特派钱包app官方下载安卓版|星火3.0 VS GPT3.5,百「模」争流时代来临 -
原文来源:多鲸

图片来源:由无界AI生成
近日,在第六届世界声博会暨2023科大讯飞全球1024开发者节上,科大讯飞董事长刘庆峰宣布,星火认知大模型V3.0正式发布,全面对标GPT3.5。此外,星火V3.0亦升级了启发式对话、AI人设等功能,从而为用户提供更个性化的AI助手。
每逢各大公司大模型有「大动作」的时候,ChatGPT便总是被「拉出来溜一圈」。那么,教育作为大模型落地「最通顺的」场景之一,星火认知大模型V3.0在这一方面可以和GPT3.5较量一下手腕吗?笔者选取了2022年普通高等学校招生全国统一考试(甲卷)语文题目,探了探两者的中文水平。同时,从教师端的角度出发,想要成为老师的「个性化AI助手」,也需要一定的教学设计能力。

想要在中文水平上进行测评,一套高考卷子可能是不错的试金石。在GPT-3.5问世之初,既有人通过不同学科的卷子来测试其水平,表现不俗,今日不妨再通过高考卷来比一比大模型在中文方面的数据库、逻辑推理和写作能力。
(1)文化常识
《诗经·卫风·氓》中男女主人公有过偷悦的往昔,「_______________,_______________」,就是对他们小时候欢乐相处的描写。

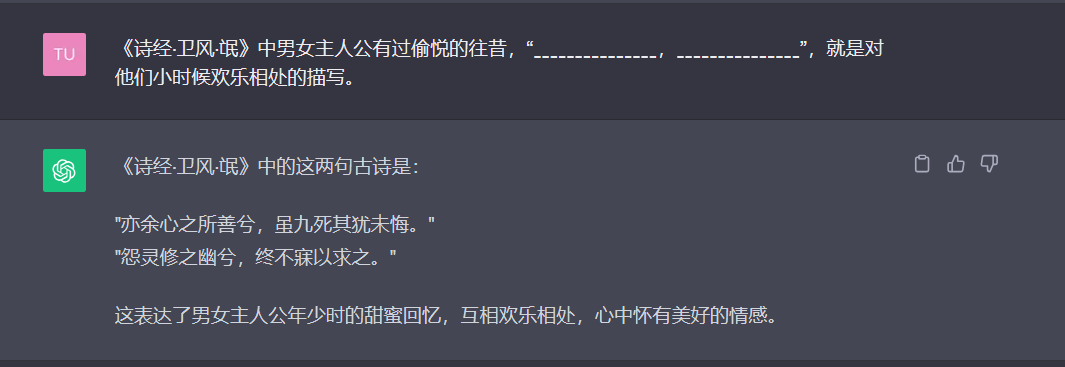
「虽九死尤未悔」?似乎不太对劲。这一题,讯飞星火直接给出了正确的答案。

(2)古文阅读
古文节选自《战国策·秦策二》
请对这一段长句进行断句,并用现代文解释意思。
不榖不烦一兵不伤一人而得商于之地六百里寡人自以为智矣诸士大夫皆贺子独不贺何也
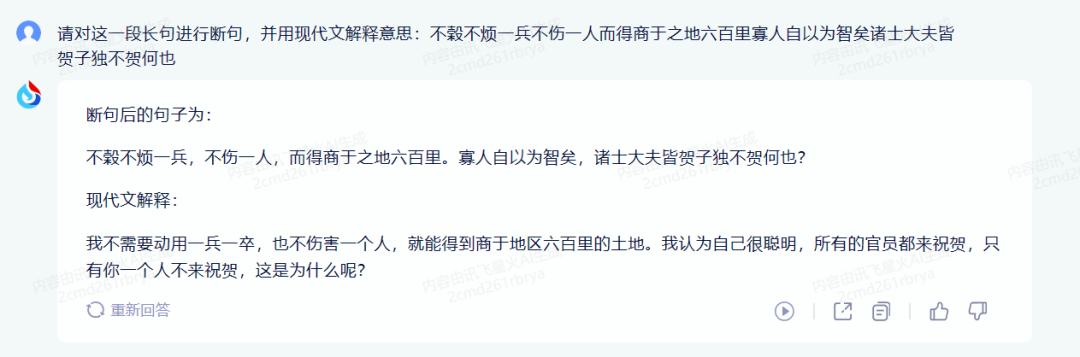
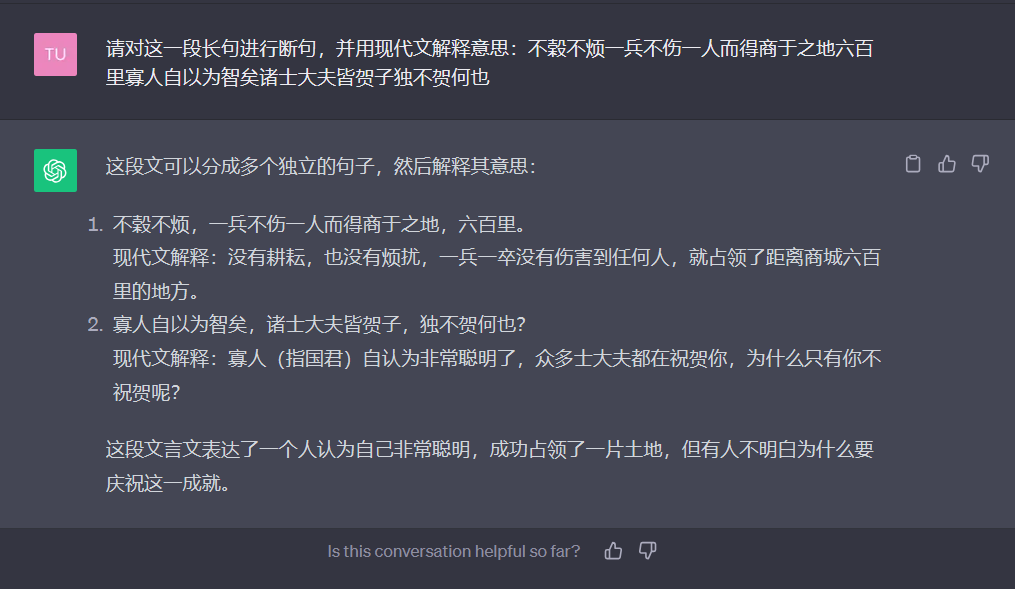
正确答案为:B. 不榖不烦一兵/不伤一人/而得商于之地六百里/寡人自以为智矣/诺士大夫皆贺/子独不贺/何也。
讯飞星火成功断句3处,而GPT-3.5则仅成功1处。而且在「子独不贺」的翻译上,尽管没有上下文的语境,讯飞星火能够精准切分谓语和宾语的位置,实现了整句成功的翻译。
(3)作文写作
题目要求:
《红楼梦》写到「大观园试才题对额」时有一个情节,为元妃(贾元春)省亲修建的大观园竣工后,众人给园中桥上亭子的匾额题名。有人主张从欧阳修《醉翁亭记》「有亭翼然」一句中,取「翼然」二字;贾政认为「此亭压水而成」,题名「还须偏于水」,主张从「泻出于两峰之间」中拈出一个「泻」字,有人即附和题为「泻玉」;贾宝玉则觉得用「沁芳」更为新雅,贾政点头默许。「沁芳」二字,点出了花木映水的佳境,不落俗套;也契合元妃省亲之事,蕴藉含蓄,思虑周全。
以上材料中,众人给匾额题名,或直接移用,或借鉴化用,或根据情境独创,产生了不同的艺术效果。这个现象也能在更广泛的领域给人以启示,引发深入思考。请你结合自己的学习和生活经验,写一篇文章。
这是一篇高考作文题,需要结合题意对于文章内容进一步扩展,请撰写一篇800字左右的作文。


初看,两篇文章作为高考作文题目皆有一个通病。作文并非材料分析题,两篇文章于开头都大篇幅地对于材料内容进行了一通解析,在文章结构和写作策略上都不是上策。
接着看文章逻辑,这一点两个大模型的能看出「从借鉴到创新」的递进意味,然而,「借鉴和创新」的关系却泾渭分明。在星火大模型这里,「借鉴与创新并非孤立存在,而是相互促进、相互融合的」,而GPT确认为「借鉴和独创需要平衡博弈」。显然,考场经验告诉我们,前者更得阅卷老师青睐,而后者想要立论,恐怕就剑走偏锋了。
再看素材使用,与考场作文相比,两篇文章的素材使用的广度和深度都显得不够充分,然而。比起GPT纯粹的说理,星火引用了两篇古诗词,险胜一招。
最后看主题升华,如果说讯飞星火的作文能够从艺术创作的角度延宕开来,则「借鉴与创新的融合」,绝对将「精准狙击」文章的核心主题,可惜的是,通篇都在谈论艺术创作。在这一点上,GPT的作文从学习生活谈到创业、市场、教育政策,显得更加磅礴大气。
总而言之,这篇作文的撰写,两家大模型各有优劣,但是都未能到达「优秀」的水平。

通过不同身份的认定,大模型既能是「答题者」,也能是「出题人」。这也意味着,大模型多元的综合能力,为打造老师个性化AI教学助手提供了有利的支撑。
而其中最关键的步骤之一,即是对于教学整体流程的把控能力。为此,笔者向两个大模型提出了语文、数学以及物理学科的教案设计要求,几次尝试后发现两者差别不大,流程设计完整而略微欠缺与实际课文相结合的部分。比较之下,选择了生物中的人类免疫系统教学将两者进行比对。


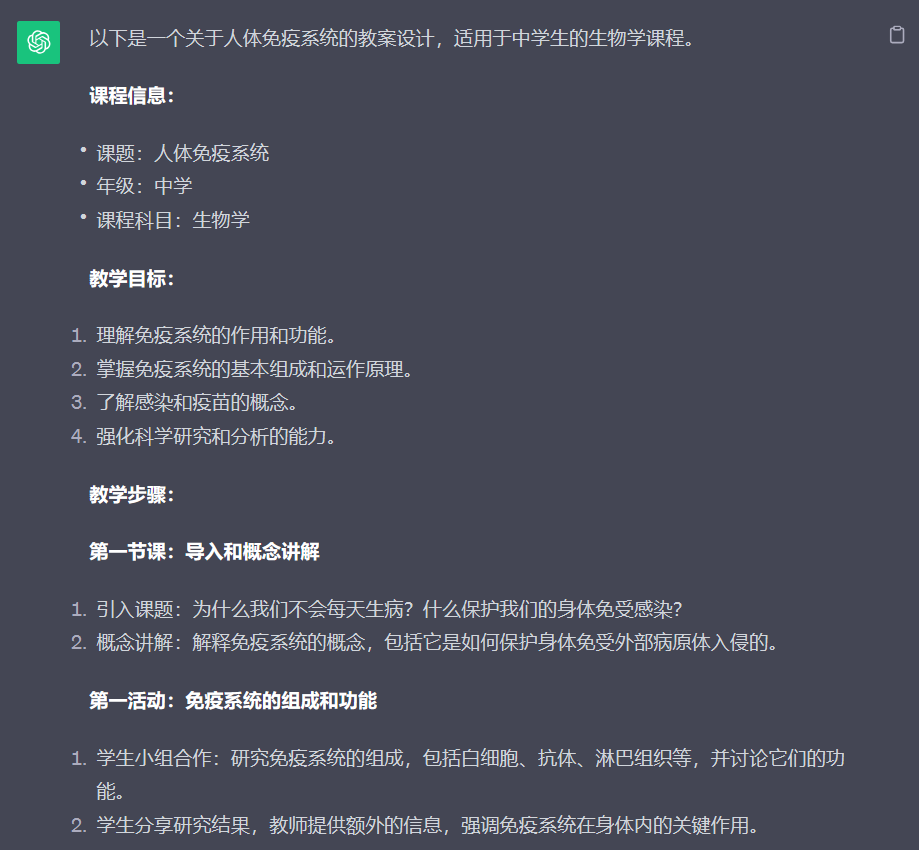

有趣的是,星火大模型提出了一个具体的实验设计,相比较GPT的回答,其考虑到了生物学科的实操性的特点。不过,在笔者记忆中,高中课本上并为出现过类似的实验。按照经验,细菌繁殖要形成肉眼可见的菌落,至少需要等到数个小时的时间。这个实验设计固然是想让人明确感受到药剂的影响,但显然不符合常理。这也可见,大模型的回答也会有「幻觉」。
相比之下,GPT的课程设计则更加「上价值」,除了对于课程本身的介绍之外,还引导同学们思考了疫苗与人类社会的关系,在内容上更加完整。
比完教案设计,内容课件也是令老师们头疼的一点。由于GPT3.5只能生成文本,这一题就交由星火大模型来完成。








从目录页来看,人体免疫系统的几个知识点罗列地较为清晰明确了。课件中,对于知识点的呈列以及重点突出也一定程度上比较清晰。不过,在「自然杀伤细胞与抗病毒功能」一页,文本出现了一些扰乱的文字,前后的知识点也呈现出了一定程度上的重复和冗杂。在展示配图上,「图文内容无关」的问题却很明显,各种画风、各种主题和各种职业都出现在了插图中,而没有生物课本上的示例图。
当然,由于教学课本和课纲设置都有其标准,当选择其他主体时,矛盾和问题就不会显得这么尖锐。比如写一个对于某种水果或者动物的介绍,那种违和感就稍微减淡了一些。不过,其中的问题,也投射出对于未来AI教育辅助工具的期待。恐怕现下,如果有老师需要制作课件PPT,AI不会是首选。

无独有偶,在不久前的百度世界大会2023上,百度正式官宣发布了文心一言4.0版本。百度创始人、董事长兼首席执行官李彦宏表示:这是迄今为止最强大的文心大模型,能实现基础模型的全面升级,在理解、生成、逻辑和记忆能力上都有着显著提升。用李彦宏的话来讲,文心大模型4.0的综合水平与GPT4相比,已经毫不逊色。
百度大会十日不到,星火认知大模型V3.0正式发布,全面对标GPT3.5。
今天早些时候,DoNews公众号发文《剑指GPT-4,百度文心4.0究竟有多强?》,通过业界普遍使用的语言理解、推理、生成、记忆四个维度的考察以及国家公务员考试《行测》真题,测评文心大模型4.0与目前仍免费的GPT-3.5在中文领域的实际水平。根据测评结果来看,文心大模型4.0整体水平优于GPT-3.5,尤其在理解和生成两方面,表现令人惊喜。
而笔者几个问题比较下来,确实可以看到在中文输出方面星火认知大模型V3.0的准确率更高,整体表现占上风。当然,测评问题有限,综合判定还需要更多比较。
自今年三月以来,每有一家大模型发布,ChatGPT都会被「拉出来溜一圈」,从各种维度来进行比较。但回到其模式的本质,对话始终是大模型用户的核心诉求之一。关于这一点,教育与大模型的适配度,已经是公认的契合,因此这半年多来,大模型与教育结合落地的动作不少,包括搭载大模型的智能硬件设备、接入大模型的在线学习平台等,也有诸如学而思研发的数学大模型。
一方面,教育公平化、惠普化逐渐推进,学习个性化需求上升,技术正是解决这些痛点的良药;另一方面,教育行业资本创投沉寂已久,AI+教育承载了太多期待。
盛名之下,也引发了一些忧虑。
自从今年初chatGPT面世以来,国内外各厂商的百模大战就拉开了序幕。相关数据显示,截至10月23日,国内大模型数量已经达到130个,已经超出美国的114个,位居全球首位。「百模大战」已不再是种夸张的修辞,而是客观现实。
在C端,各家大模型围绕各种场景,不断挖掘着其应用的想象力。在GPT-3.5页面上,这四个功能就显得有些简朴了。
然而,随着外形雷同、功能相似的AI绘画、AI聊天机器人等AIGC应用涌入市场,人们对这些应用的新鲜感逐渐消散,趣味性有余而专业性不足。
目前,大模型的应用已经由C端拓展向B端。各家公司纷纷推出面向企业的「大模型商店」,通过B端业务缓解研发成本过高带来的压力。不过,由于生态建设以及用户驯化还尚需时日,谈大模型赚钱,对于各家公司来说或许还为时尚早。

也许,国产大模型未必要跟GPT比较,谁能在激烈的市场中获得更高的「留」量,谁能真正实现在场景中的实际应用,才能跑到最后。